
There are already plenty of articles out there on the effects that iOS 14.5, and IDFA deprecation, have had on performance marketing. These are articles about how Apple's changes have shifted the burden of attribution modelling onto ad platforms, decreased the effectiveness of ad targeting, and caused shifts in CPM pricing across iOS and Android devices.
One consequence of iOS 14.5 which has received fairly little attention, however, is the effect that the changes have had on conversion lift testing. Lift tests used to provide a gold standard of incrementality measurement for Facebook advertisers, but now they've been entirely deprecated with no alternatives offered.
Let's take a look at what conversion lift tests are, why they were deprecated by Facebook, and how geo-experiments offer a way forward.
What are conversion lift tests?#
Conversion lift tests (or simply lift tests) are the marketing equivalent of a randomised controlled trial.
They try to understand the impact of an ad campaign by randomly showing it to one group of users, with-holding it from another, and looking for a difference in behaviour between the two groups over some predetermined period of time.
What difference in behaviour do lift tests look for? This is entirely up to the advertiser that's running the lift test. A typical ecommerce brand might want to understand whether their Facebook ads are driving sales that wouldn't have happened anyway, and so they'd want to track purchases as a KPI in their lift test.
Control & treatment groups#
If the group of users that has seen the ecommerce brand's ads (the treatment group) go on to purchase from that brand at a greater rate than those who haven't seen the brand's ads (the control group), then this would indicate that the campaign has generated incremental sales.
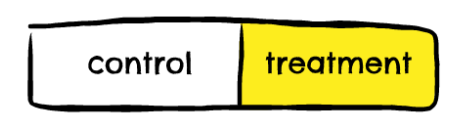
If the above isn't true - i.e. the treatment group is no more likely to purchase from the brand than the control group - then the campaign can be said to have generated no incremental sales. In this case, any sales attributed to the campaign (via post-click or post-view attribution) were likely sales that would've happened anyway.
How much incrementality?#
Just because a campaign generates incremental results doesn't mean it's a campaign worth running. To assess that, we need to understand the campaign's cost per incremental conversion.
Let's say, from the example above, that the ecommerce brand spent $100k on their campaign. They measured 7,500 sales from their campaign's treatment group (both during and for some fixed time after the campaign), and 5,000 sales from their campaign's control group.
Simply put, the difference between these sales numbers (2,500) is an estimate of the number of incremental sales driven by the campaign. If we divide the campaign cost by the number of incremental sales, we get an estimate of the cost per incremental purchase (CPiP); $40.
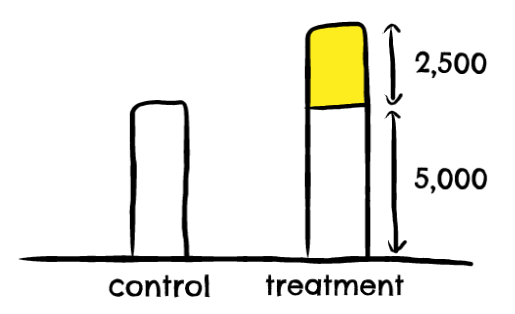
If this CPiP is tolerable to the brand (meaning it's lower than their LTV, and they're happy to acquire customers at that price) then the campaign can be considered success. Note that if the difference between the treatment and control group sales was smaller, the CPiP would be proportionally higher, and so the likelihood of the campaign being successful decreases.
The death of conversion lift testing#
A fairly crucial part of being able to run a conversion lift test is being able to measure conversion volume from two groups of people; your treatment group (who've seen your ads) and your control group (who haven't seen your ads).
IDFA deprecation, ATT, and SKAD Network don't on their own provide any reason why you wouldn't still be able to report (or at least estimate) conversion volume for your treatment group. They introduce some limitations on the time delays between ad interaction and conversion, and require you to have at least a small observation period in which conversion postbacks can trickle in. That said, there are no fundamental reasons that they prevent you from measuring treatment group conversion volume.
The situation is more complex for measuring control group conversion volume; that is, the number of purchases from a group of users who haven't seen a brand's ads. For various reasons -not least that SKAD Network postbacks require a campaign ID for the conversion to be attributed to- it's just not possible to measure the conversion volume from a lift test's control group.
Having the conversion volume for a lift test's treatment group, but not its control group, is of little use. As we saw earlier, it's the difference between these numbers that's of actual interest, and so having just treatment group conversion volume is even less useful than regular post-interaction attribution methods (as it ignores time between conversion and ad interaction).
Facebook's response#
While Facebook did announce earlier in the year that advertisers wouldn't be able to create new lift tests after the roll-out of iOS 14.5, they did little to publicise this fact. Along with a small note in the Experiments pages found within Ads Manager, Facebook made only minor edits to their lift testing documentation to warn advertisers of the upcoming changes.
Facebook suggested that advertisers replace lift tests in their measurement strategy with regular A/B tests (which offer no way to measure incrementality) or brand lift tests (which seek to measure a campaign's impact on brand metrics, not conversions). This is tantamount to Facebook giving up on conversion lift testing, and forcing advertisers to find other ways to measure the incrementality of their campaigns.
Cue Geo-Experiments#
With conversion lift tests off the table, advertisers are back to the drawing board in search of a new methodology to measure the effectiveness of their campaigns.
Although there is no causal inference method that can be considered the universal "next best option", geo-experiments are particularly suited for online advertising; they have strong statistical rigor and are easy to understand, design, and implement.
What are geo-experiments?#
Geo-experiments are a quasi-experimental methodology where non-overlapping geographic regions (geos) are randomly assigned to a control or treatment group. Thanks to geo-targeting, ads are served only in the geos of the treatment group while users in geos of the control group won't be exposed to the advert.
As a simple example of what this might look like, we might run a state-level geo-experiment in the US by randomly assigning each state to either a control or treatment group. We'd then run our ads in the states which make up the treatment group, while keeping our ads paused in the states making up the control group.
How do you implement a geo-experiment?#
Setting up Geo-experiments is pretty easy assuming that you can target ads to the relevant level of location (neighbourhood, city, state, etc.) and measure conversions at a geo-level. All the major ad networks/tracking platforms allow for these features.
Step 1: Geo identification#
The first step is deciding the level of granularity you'd like to run your test at.. If your market of interest is the whole United States, it might make sense to have the states as your geos. If your market is a state, you can use DMAs or zip codes to break down your region of interest into smaller areas.
To ensure statistical robustness of the measurement, it's advisable not to select geos that are too small (_i.e. z_ip codes) as people may travel across geo-boundaries and the volumes of conversions may be too low.
Step 2: Geo randomization and assignment#
Once we have defined our market and its partitioning we need to randomly assign each geo to the treatment or the control group.
In an ideal scenario, where all the geos had a similar performance in the past, randomization is fundamental as it ensures the minimization of the possible differences between the two groups aside from the ad serving. This functions as a guardrail against biases.
The idea is that before the launch of the campaign (pre-test period) the treatment group and the control group are as similar as possible and they differ only for one factor in the test period; the exposure to the ad.
However, differences in geos can be present, and harm the design & accuracy of the test. For this reason, a preliminary analysis is often required so that we can find which are the best geos to include in the treatment and control groups.
How to Measure a Geo-Experiment#
Once we have set up the experiment we can use econometrics methodologies such as Difference in Differences or Synthetic Controls to quantify the ad incrementality; how many conversions would not have happened if the ad was not served.
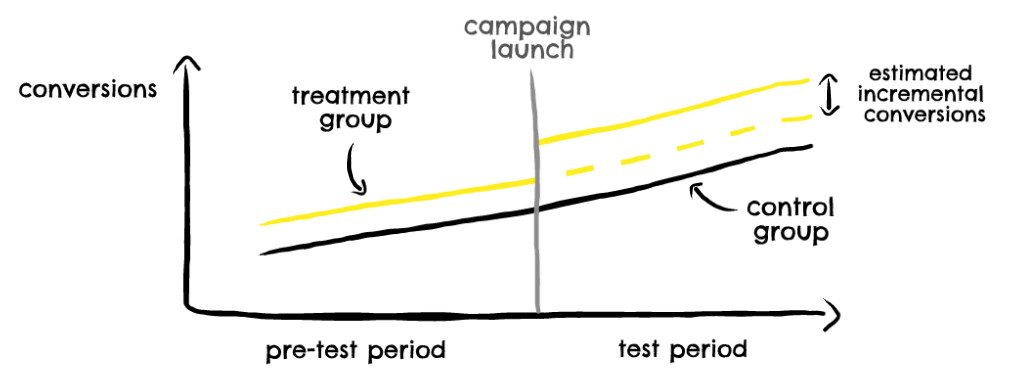
The intuition behind these methods is simple:
- We estimate the counterfactual of the treatment group in the test period: what would have happened had the intervention not taken place (dotted yellow line)
- We calculate the difference between the actual treatment performance (solid yellow line) and the counterfactual
Although the results coming from this methodology won’t be as accurate as conversion lift tests, geo-experiments are a future-proof way to measure ad effectiveness as they don't require user tracking and can be applied to different channels. This even includes offline channels.
There are tons of tutorials online to analyze quasi-experiments results and a technical walk-through is out of the scope of this article. With basic coding skills, Marketers can leverage very abstract packages such as CausalImpact (developed by Google) or its enhanced version, MarketMatching.
Recently Facebook released GeoLift, a new open-source package to measure lift through geo-experimentation.
Looking Forward#
While geo-experiments require slightly more technical work to design, set up, and run, they offer a clear path forward for marketers looking to replicate conversion lift tests. While no ad platforms offer out-of-the-box geo-experiments, Facebook have toyed with the idea in the past in private betas, and it's possible they might make such tools public in future.
Until that point however, it's worth familiarising yourself with geo-experiments as a tool to measure incrementality, especially with conversion lift testing no longer available on platforms like Facebook.